Accelerate Enterprise AI Path to Production
Alluxio Enterprise AI is a new product architected for AI. We bring your data to AI so that you can seamlessly access, manage, and run your AI/ML workloads anywhere.
wHAT’S NEW
AI/ML Infra Meetup @ Uber Sunnyvale & Hybrid | Thursday May 23, 2024
Join leading AI/ML infrastructure experts from NVIDIA, Uber, Uchicago, and Alluxio for the AI/ML Infra Meetup hosted by Alluxio and Uber. This is a premier opportunity to engage and discuss the latest in ML pipeline, AI/ML infrastructure, LLM, RAG, GPU, PyTorch, HuggingFace and more.
Immerse yourself with learning, networking, and conversations. Enjoy the mix and mingle happy hour in the end. Dinner and drinks are on us!

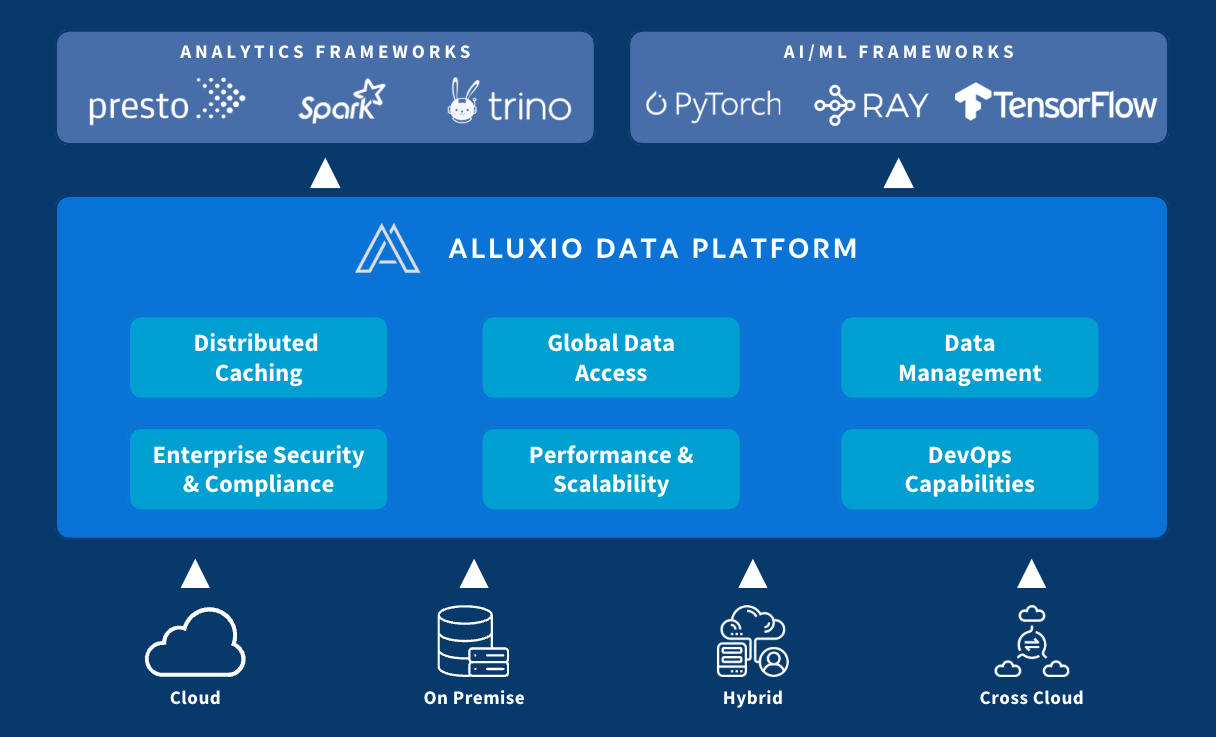
The Alluxio Data Platform powers many of the most critical data-driven applications in the world.
Why Alluxio
Uniquely positioned between compute and storage, Alluxio provides a single pane of glass for enterprises to manage data and AI workloads across diverse infrastructure environments with ease. Alluxio Data Platform has two product offerings – Alluxio Enterprise Data and Alluxio Enterprise AI. Choose the product offering based on your workload’s needs, and enjoy epic performance, seamless data access, simplified data engineering, and cost savings.
Epic Performance
Accelerate model training by 20X and model serving by 10X.
Maximize Infra ROI
Build on existing data lakes. 90% + GPU utilization.
Seamless Data Access
Eliminate data copies.
Access data seamlessly anywhere.
Data and AI Infrastructure Challenges
Analytics
Data is siloed across different storage systems, clouds, and regions
Data is often remote from the application leading to low performance. Replicating data introduces additional data engineering complexity and costs.
Managing different tech stacks is costly and complicated
Whenever new storage is introduced application developers may need to rewrite applications to accommodate new storage protocols. The myriad storage options require too much labor to maintain and operate. Poor user experience leads to increased user complaints to the data platform team.
Cloud and network costs are difficult to manage and predict
Everytime data is replicated from one silo to another, costs are incurred. API costs and egress costs add up over time and are difficult to predict.
AI/ML
Data infrastructure cannot meet the demands of AI
Data infrastructures are not built to meet the requirements of AI workloads. Data platform teams are tasked to retool the data infrastructure and introduce costly hardware such as high performance computing or specialized storage.
GPUs are scarce and often underutilized
GPUs are in short supply, and training often happens wherever GPUs are available. When training datasets are remote from the GPU clusters, data loading is very slow, wasting GPU cycles. Copying data introduces data engineering complexities.
Data access is slow and models are starved
Models often need to ingest data from multiple sources with different protocols. Thus data is often remote from the models, introducing I/O bottlenecks. Metadata operations on a large number of small files also causes low performance, stalling the training pipeline.
Trusted by the World’s Leading Organizations

“Alluxio has proven to be a valuable solution in addressing the data access challenges of hybrid cloud for Comcast. It has provided us with faster data access, reduced egress costs, and streamlined data management, resulting in more efficient and effective data value creation for the organization.”

“At Uber, we run Alluxio to accelerate all sorts of business-critical analytics queries at a large scale. Alluxio provides consistent performance in our big data processing use cases. As compute-storage separation continues to be the trend along with containerization in big data, we believe a unified layer …”
“With the introduction of Alluxio, we are seeing better performance, increased manageability, and lowered costs. We plan to implement Alluxio as the default cross-region data access in all clusters in the main data lake.”
End-to-End Machine Learning Pipeline Demo
Alluxio’s Senior Solutions Engineer Tarik Bennett walks through a short end-to-end machine learning pipeline demo with Alluxio integrated. See how Alluxio can be provisioned or mounted as a local folder for the PyTorch dataloader, delivering 90%+ GPU utilization and dramatically accelerating data loading times.
1. Data Preparation
2. Setting up the Model
3. Setting up the PyTorch Profiler
4. Model Training

Ebook
PyTorch Model Training & Performance Tuning

PRODUCT DEMO
Solving the Data Loading Challenge for Machine Learning with Alluxio

WHITEPAPER
Efficient Data Access Strategies For Large-scale AI
Sign-up for a Live Demo or Book a Meeting with a Solutions Engineer